
The value of PSD theory for powder manufacturing
文章长期更新中
目录:
- 概述
- 通过粒度分布数学函数预测结果的真理性
- 分布函数的数学符号
- 常用峰型粒度分布函数
概述
粒度分布理论是主要用于描述粉体系统由于其PSD变化从而对粉体的后续行为(如堆积、比表面积等)以及使用性能(如粉末冶金、热等静压、3D打印下初始粉末尺寸分布对组织的影响)产生影响的基础数值模型。
通过这些数学模型,颗粒系统的粒度分布连续谱可以被精确表征,从而获得光滑、连续、无限可微的数学曲线,使所研究的对象从具体的颗粒系统抽象成其所映射的数学合集,由此便可以通过数学工具对颗粒系统的行为(碰撞、堆积、测算)做有效模拟。
由于这种数值计算总是“全员参与”的,因而其可从根源上避免一般测量手段(如激光粒度、筛分,图像法等)难以规避的取样误差问题。
举例来说,粉体的一般测量手段,由于误差的不可避免,其所观测的结果总是不稳定的,类似于近视者看不清远处;而粒度分布理论在合理“聚焦”后,其所展现的是清晰的结果,如同“戴眼镜”,为观测者带来充满细节表现的体验。有经验的工程师,会很清楚这些清晰的“细节”对于下游应用,如热等静压PSD微调,3D打印调参具有极大方便。
“我们都清楚做试验的思路是让某个变量x变化来观测结果y的变化,但具体的工程问题是,x和y的可调变化幅度都往往很小,以至于若我们变动x很小时,我们根本难以判断y的变化到底是随机跳跃还是真的那个趋势,万一y的变化由于随机变动正好与真理相反,那试验结果反而会误导我们”
——某工程师体验
现在,粒度分布理论能在很大程度上协助工程师消除这种不确定。
通过粒度分布数学函数预测结果的真理性
自然界中的许多实际物理过程会存在某种分布,如在统计之中所常用的正态分布(Normal Distribution),其可以根据已知的[平均值]和[标准差]即可得到一个对称的单峰形分布。统计学基于正态分布假设,对多数的自然过程的数据均可进行相应的分析。
但问题在于,我们所依赖的数据,为什么会呈现正态分布?或者说,我们所以使用的数据,呈现某种既定的分布的真理性何在?
一种较为合理的解释,是从信息论的角度出发,以[最大熵原理]对这种情况进行诠释。以文字的形式则描述为:
“所谓最大熵原理,可以认为其所得到的分布为限制性条件下的最大可能分布”
——最大熵原理下的分布
在信息论中,对于某个频度分布p(x),其信息熵可以按照式(1)计算:
(1)
上式表示了对于某个分布p(x),其所蕴含的信息熵。而p(x)分布则通常还需包含一些其他的约束条件,从而使得p(x)不能呈现任意分布。因而在数学上,人们很自然联想到条件极值的处理手段,以拉格朗日乘因子法(Lagrange)对易于函数化的问题进行条件极值处理。
显然,对于一个频度分布p(x),比如我们对应为颗粒在尺寸x上出现的概率,那么作为分布函数,其频率分布在整个定义域的积分应当为1,即必然满足如下条件:
(2)
我们假设p(x)还应当满足其他条件,且这些条件可以写成相应的数学形式,则由拉格朗日乘因子法,有:
在式(3)中,Ci表示关于分布p(x)的具体条件。对上式求导取0,并依据已有的其他条件,即可获得假定在S最大情况下的p(x)分布的具体函数形式,即分布的最大熵假设。
已有的科研结果表明:
(1) 当未加入其他约束时,p(x)为均匀分布;
(2) 当统计变量有一确定的数学期望和方差时,最大熵分布p(x)为正态分布。
(有兴趣的读者可以依据上述方法和条件对函数的获得进行推导)
在长期的检验之中发现,我们所使用多数分布函数,均可以通过此类方法进行推导得到,因而,我们可以大胆确信:
“对我们所研究的粒度分布,若它受到某些条件的约束,它必然可以导出成某种符合该条件的最大熵分布,因而其必须呈现某种特殊的数学函数形式,这种情况是最大可能的”
——最大熵原理下的粒度分布可函数化
分布函数的数学符号
在前文的讨论之中,我们将频率分布函数视为p(x),其对应的累计频度分布函数则对应其函数字符大写为P(x),这种例子对应于经典的概率统计对分布函数的要求,这些分布函数满足:
(4)
(5)
(6)
(7)
对于颗粒的粒度分布来说,有两种基本分布:
(1) 质量/体积分布: 即与颗粒尺寸x相关的质量/体积分布,其对于密度均一的体系是相等的,这与多数我们遇到的颗粒系统相同;若颗粒的密度不均匀时,则需要特别对待;
(2) 个数分布: 即与颗粒尺寸x相关的个数分布。个数分布通常在颗粒尺寸的上下限相差不大时,具有精度非常高的统计意义,如精确筛分的窄区间颗粒体系(比如轴承滚珠,圆珠笔头等),但对于颗粒尺寸差异过大的体系,则个数分布往往与直接使用的感知不同,此时细小的颗粒会占据统计之中过多的失真部分。
为便于讨论,我们通常不使用p(x)与P(x)函数来定义频度分布和累计频度分布,因为他们不能直接看出是具体的哪种分布。因而我们需要利于辨认的符号将两种完全不同的分布区别开。
通常我们使用f(x)与F(x)来表示质量/体积分布,函数符号f表示fraction, 即筛分的占比。
当需要使用个数分布时,我们通常使用n(x)和N(x)表示,函数符号N表示number,代表颗粒的个数。
一般来说,对于颗粒科学的大多数情况,若不经特殊声明,我们在讨论分布时,均遵循如下原则:
(1) 申明的是质量分布而不是个数分布;
(2) 认为质量分布与体积分布相等。
常用峰型粒度分布函数
为解决将真实的粒子系统进行数学化和模型化,使用合适的粒度分布函数(Particle Size Distribution Function)以对真实粒子系统进行替代是必须的。若要将粒度分布能够进行替换,则需要满足如下假设:
(1)该粒子系统的每个单样本均是普通的。即每个颗粒不应当具有显著的特殊性,但他们的某些性质,可以以一定规律浮动。例如,通常我们处理的样本,我们要求绝大多数样本的密度应当是相同的,否则会影响到质量/体积分布与颗粒分布转换的稳定性。
(2)该样本本身应当具有代表性。如前所述,颗粒系统来自于雾化过程,在最大熵原理的约束下,平均来看,颗粒系统应当满足某种分布。但这一“满足”是针对全部粒子系统来说的,若我们实际所测量的样品由于取样的混沌性不能满足这一要求,那么事实上取样的检测结果的精度上限并不如直接数值分析更合理。
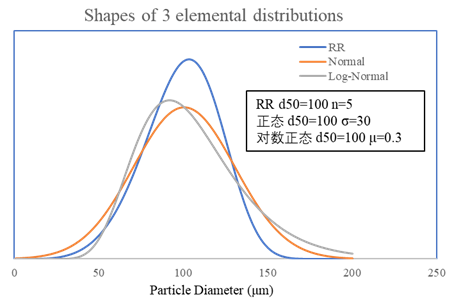
长期的工程实践表明,有如下3种分布是极具代表性的
- 正态分布(Normal Distribution)
(8)
- 对数正态分布(Logarithmic-Normal Distribution)
(9)
- Rosin-Rammler分布
(10)
一般来说,对于单一雾化机制,其体积分布通常呈现为正态分布。但在许多研究报告中,为便于求解,研究人员也常常使用Rosin-Rammler分布作为峰形函数,这是由于Rosin-Rammler分布函数在一定条件下,其峰形与正态分布接近,且其函数形式更适合求导与积分,从而便于做计算推演。
但需要说明的是,除却正态分布以外,在粒度-体积曲线上,对数正态分布与Rosin-Rammler分布均不是对称分布,其总是偏态的,其峰值一般来说偏左(即峰值相对于正态分布,靠近小值)。
No responses yet