在确保开始前,请先确认您的PSD-PREP已经被正确部署,且对于文中所提到的功能,您当前的license对其具有权限。
在开始前的激活准备,请参考(若您已准备好,请跳过):
开始执行计算的准备工作,请参考如下已有指导:
关于首次使用,请参考:
通过该功能,用户可以检查已经计算的粒度分布的任意区间(a, b)的2D视场。这些计算基于MC方法,通过已有校验的粒度分布以数学方式生成,其具有数值上的合理性。一般来说,若实际的2D视场与数学计算结果存在较大差异,则通常有如下可能:
(1) 原始粒度分布频谱未校准
(2) 用户实际检测的筛分粉末取样不准确(这与筛分的原因有关)
由于筛分的取样混沌性,即便符合技术标准的测定手段,也在科学上难以保证取样的稳定性,这一问题将在筛分测算模型中被详细讨论。事实上,这是一个困扰粉末领域的长久问题。
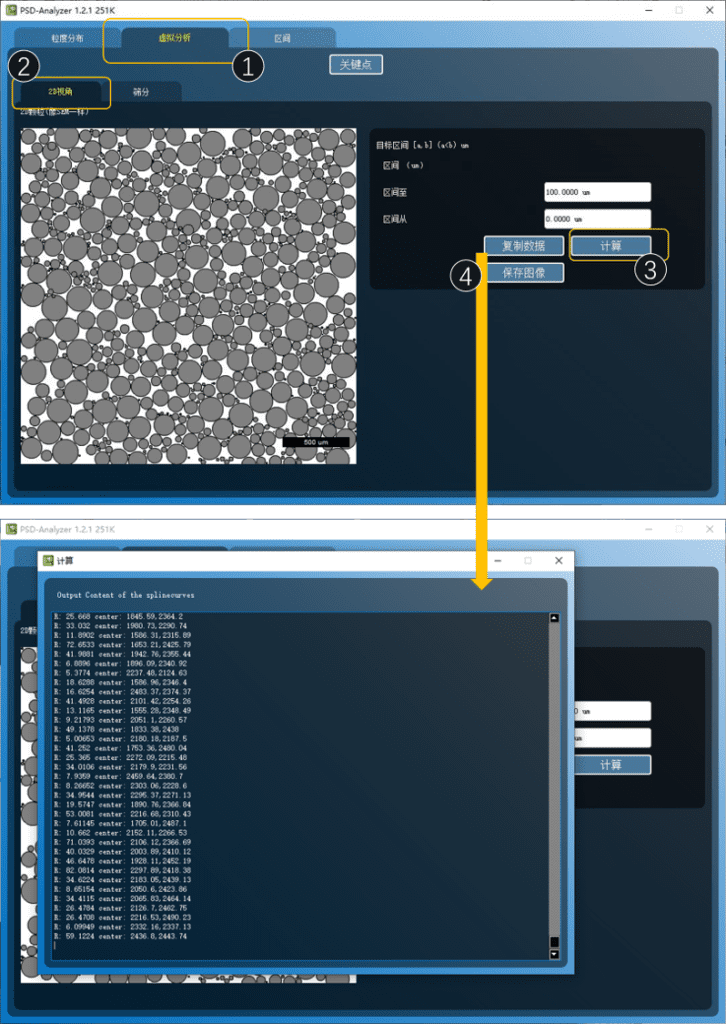
在[虚拟标签]=>[2D视角]中,通过设置区间上下限(例如0-100μm),单击[计算]按钮,则可通过PSD-Analyzer对已经载入程序的粒度分布仅0-100μm段的颗粒的2D堆积特征进行绘制与描述。
需要说明,此处选择的颗粒的区间(例如0-100μm),是通过先前计算得到粒度频谱,仅将其目标区间段的粒子截获并转换为个数分布后呈现的结果,其应当与常规的光镜或SEM视场保持一致。
额外的,用户可以通过[复制数据]获取生成的随机堆积的具体分布,其每行内容分别表示独立的圆数据:
R: [半径] center: [圆心坐标]
用户可将上述数据导出进行其它计算,该数据的单位为默认的μm。
得益于与PSD-Analyzer的配套,针对PREP粉末的筛分趋势,也可以被数值方法捕捉。
在[虚拟标签]=>[筛分]中,用户可通过设定如下参数,单击[计算]以完成一次筛分分析(相对粒度分布分析)
筛分所需要设置的主要参数如下:
区间值: (1) 从a至b,表示选择[a, b]尺寸区间的粉末全部纳入到模拟筛分中 (2) 注意该值应当选择全区间,例如大多数粉末在0-150μm内,则此处选择0-150;对于较粗的粉末可以选用0-250μm 筛网 a. 尺寸 名义筛网尺寸,例如对于Taylor筛,325目对应标准的45μm,依次类推 b. 标准差 (1) 考虑真实筛分过程时,筛网的孔径分布并不是完全一致的,其尺寸被假设处于1个正态分布,因而其筛网尺寸需设定1标准差 (2) 例如对于100μm筛网,标准差设置在8μm,已经是相当高质量的筛网 c. 网丝直径 对于编织筛来说,较粗的网丝直径会降低单位面积上网孔占据整个筛网面的百分比,这一参数对筛分结果影响显著,因而需通过实际测量确定后进行处理 e. 孔个数 (相对量) 这是一个可修改的参数,其主要设定了通过MC方法处理时的校准情况,其并不需要设定一个真值 校准问题在后续将详细讨论 f. 碰撞 (相对量) 这是一个可修改的参数,其主要设定了通过MC方法处理时的碰撞校准情况,其并不需要设定一个真值 校准问题在后续将详细讨论
通过进行设定后,软件可对筛分的结果进行测算。
如上图所示,不同颜色的曲线代表了粉末颗粒在不同阶段的粒度分布频谱(PSD frequency):
尽管从模型上来说,碰撞次数是最影响筛分的参数。当碰撞频率固定时,较高的碰撞次数意味着延长碰撞时间,从而使得筛分结果演化。
但问题在于,实际工程的测定往往并不能直接带入碰撞次数,一是其难以测定,二是其真值事实上非常大,不便于进行筛分计算。
但由于,在稳定的筛分体系内,可以认为质量良好的粉末必须保证[少量]取样可以代表整体分布的特点,即符合[取样标准],那就可以仅针对该[少量取样]的测算。故而,在这一条件下,利于下筛的孔个数和碰撞次数,就并不是全局值,而是一组局部粉末的值,其真值是模糊的。
因此针对这种问题,可以采取如下方式进行处理:
首先确保其它易于测量的筛网参数,原始粉末粒度分布等输入是合理的;
例如,如上图所示,当增加筛网标准差,或者延长时间(增加碰撞次数),都会导致所得粉末粒度分布的异化。且其具有较显著的差异。
上述数值实验即可表明,为何在粉体领域,筛分,特别是涉及取样的数据,很难保证同一性。除却常规的取样问题以外,被认为最可靠的筛分获取方法,会由于不同的筛分工艺方式(影响N1000)、不同的筛网状态(筛网的名义同一尺寸,也可能存在网丝差异)、同一筛网的不同声生命周期(筛网会随着使用导致其标准差增加)而产生差异。而且这些差异是较为明显的。
故而,工业上的常见现象是,同样一种被认为“合理”的检测筛网,在同样生产工艺下,可能会测得不同的结果。这里的误差主因来源于筛网的测量不稳定性。
而不同的测量厂家,由于采取的筛网标准与手段不同,极大概率获得完全不同的数据结果。
即便对同一样品,同一厂家,由于筛网会随着使用而逐渐变化,也会产生完全不同的结果。
换言之,对于精细粒度分析,通过实验测定的筛分结果,是一个参考值,而不是值得完全相信的基准,这是一个对于粉体领域而言,相对于传统科学习惯所需要特别关注的特征。对于粉体领域,这种习惯可能会导致很多麻烦。
上述失真的主要问题,在于不可还原性,即实测数据可能会丢失PSD遗传特征,使得后续数据不能精确还原原始数据的特征,这对构建精细模型带来麻烦。
Categories:
Tags:
师兄太棒啦
您的邮箱地址不会被公开。 必填项已用 * 标注
评论 *
显示名称 *
邮箱 *
网站
在此浏览器中保存我的显示名称、邮箱地址和网站地址,以便下次评论时使用。



One response
师兄太棒啦