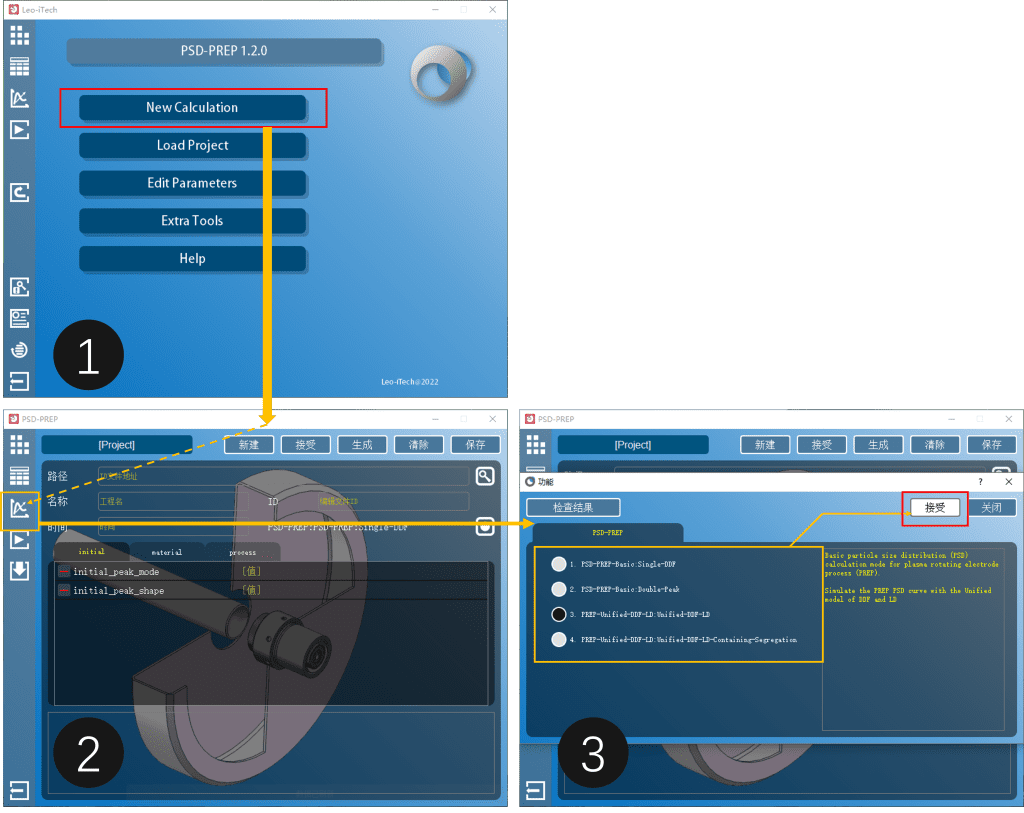
#initial
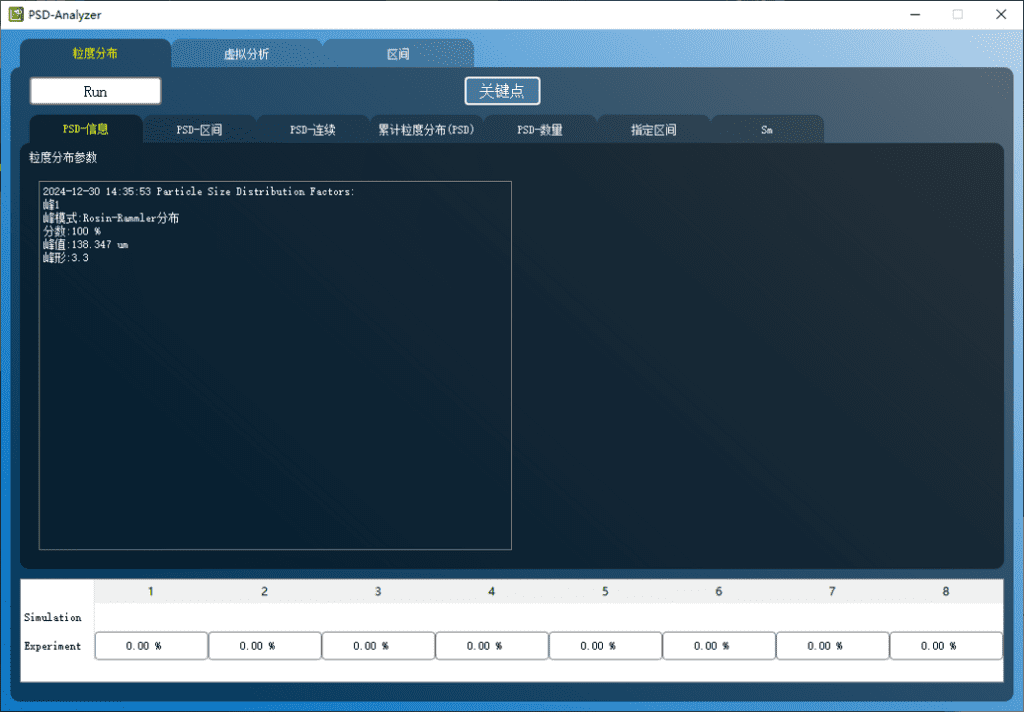
initial_peak_mode=0 #峰模式,设置为0表示使用Rosin-Rammler分布
initial_peak_shape=3.3 #峰函数的形状因子,若为Rosin-Rammler分布,在NRR假设下可近似使用3.3
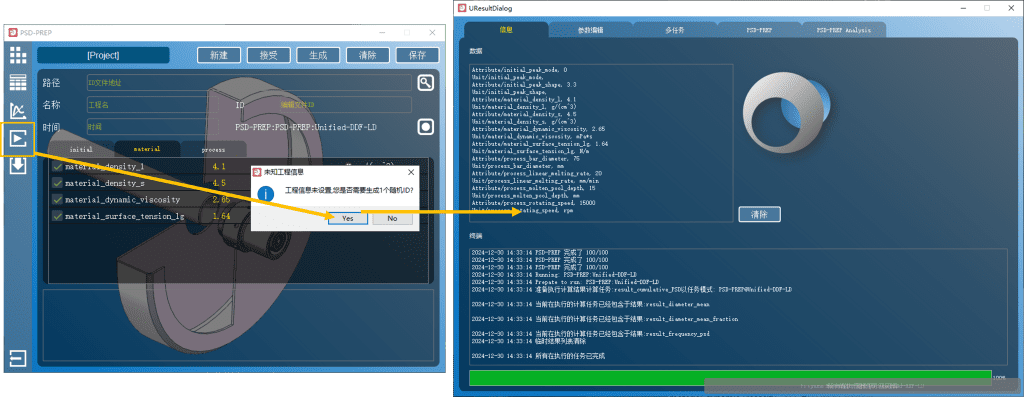
#material 选择Ti6Al4V
material_density_l=4.1 #合金液相密度
material_density_s=4.5 #合金固相密度
material_dynamic_viscosity=2.65 #合金液相动力粘度
material_surface_tension_lg=1.64 #合金液相的液气表面张力系数
#process
process_bar_diameter=75 #设置PREP的棒材直径,即熔池直径
process_linear_melting_rate=20 #设置线熔化速率
process_molten_pool_depth=15 #设置熔池深度
process_rotating_speed=15000 #设置PREP的转速

No responses yet